 Figure 1 |
 Figure 2 |
 Figure 3 |
 Figure 4 |
 Figure 5 |
 Figure 6 |
 Figure 7 |
SPEECH TECHNOLOGY MAGAZINE
October / November 1998
Advanced Human Interfaces:
Magic Words and Computers That See
KidsRoom Shows How Computers Use Speech and Vision Recognition
By James A. Larson
Inspired by the books Peter Pan, Bedknobs and Broomsticks, and Where the Wild Things Are, researchers at the MIT Media Laboratories constructed a room that guides children through an interactive, multimedia adventure. The room contains furniture, rear-projected walls, speakers, microphones, lights, and several cameras networked to several computers. As many as four children enter the room and are told to "ask the green cabinet for the magic password." From there, the children are guided to a green frog, a yellow shelf, a red chest, and, finally, a green cabinet that tells them the magic word, "Shamalamadingdong" (Figure 1). A voice tells the children to "be quiet and get onto the bed." If they fail to climb onto the bed, the voice threatens: "I’m not fooling around! You don’t want me to come up there do you? Now get on that bed. All of you!" A monster appears on the wall and invites the children to go on a big adventure, but first they must shout the magic word. After shouting the magic word, the walls of the room change to a forest scene (Figures 2 and 3). The children follow a dotted path to a river (Figure 4). The bed becomes a magic boat with images of moving water appearing on the wall. The children make paddle motions with their hands to avoid rocks in the simulated river (Figure 5). They encounter monsters who teach them how to make four "monster gestures": crouch, make a "Y," flap their arms, and spin like a top (Figure 6). Afterwards, the monsters mimic the children’s moves as the children perform the four moves in a dance (Figure 7).
Figure 1 |
Figure 2 |
Figure 3 |
Figure 4 |
Figure 5 |
Figure 6 |
Figure 7 |
Computers control the entire KidsRoom experience. The lighting, music, and animation appearing on two of the walls in the room lead the children from activity to activity. Using both speech recognition and vision recognition technology, the computers observe what the children do and encourage them to perform the appropriate actions. For a detailed description of the KidsRoom and the technology behind it, see: http://vismod.www.media.mit.edu/vismod/demos/kidsroom.
While the MIT KidsRoom is a dramatic example of how computers can use speech and vision recognition, it is not the only example. Sabbatical, Reality Fusion, and Holoplex have products that use a video camera to capture a user’s video image, manipulate the image, and, in some cases, extract semantic information to control applications.
TYPES OF RECOGNITION
Figure 8 illustrates the correspondences among three types of recognition—speech, model-based object recognition, and motion tracking/interpretation. Computer vision—both model-based object recognition and motion tracking/interpretation—enables the blind computer to see. Model-based objection recognition detects objects, while motion tracking/interpretation determines what the objects are doing.
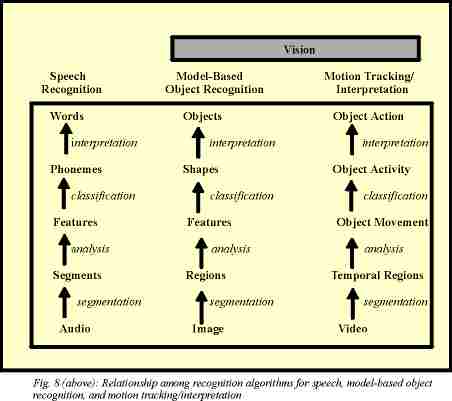
Speech Recognition. For a computer to recognize words from human speech, a series of algorithms process the raw acoustical signal to extract features, classify phonemes, and recognize words. These algorithms are listed in the left column of Figure 8. Digitizing and segmenting algorithms convert the raw audio signals to segments; while Fourier, cepstral, and linear predictive analysis algorithms extract features such as the fundamental frequencies and formants. Classifying algorithms process the features to generate phonemes, which are then combined and interpreted into words.
Model-based Object Recognition. The center column of Figure 8 lists the algorithms used to classify regions within an image into features, shapes, and, finally, objects. Segmentation algorithms divide the image into regions and extract features such as color blobs or edges, which are then classified into shapes. Multiple shapes may be combined and interpreted as objects.
Motion Tracking/Interpretation. The right hand column of Figure 8 lists the various video motion algorithms that recognize object movements, activities, and actions. Applications use movements, activities, and actions as input from the user, either in conjunction with or in place of more traditional forms of input via the keyboard, mouse, joystick, or microphone.
MODEL-BASED OBJECT RECOGNITION
Object processing algorithms include background elimination and substitution algorithms, shape recognition, and face recognition.
Video Background Elimination and Substitution Algorithms. If the video camera is stationary, the background behind a person in a static image can be removed. First, with a fixed-positioned video camera aimed towards a scene, the camera captures an image of a scene with no one in it. Next, the camera captures a picture with a person in the scene. Subtracting the values of corresponding pixels in both images, pixels with values close to zero represent the background and pixels with larger values represent the person. The pixels with values close to zero can be replaced by pixels of another scene, which, in effect, places the person into another scene. This process, sometimes called background substitution, has similar goals to the process of chromakey,™ or blue-screen technology, used in television and movie studios. However, with background substitution, the blue-screen is not used.
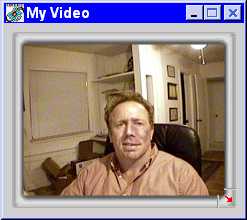
Background substitution can be used in conferencing applications to hide the user’s real background and replace it with a more impressive background. It can also be used to superimpose a user’s image over a PowerPoint presentation or other graphics to which the user can gesture, much like a weatherperson’s image that is superimposed over a weather map on television. In interactive adventure videos, the user’s image can be overlaid on an appropriate scene in the adventure, such as the steaming jungles of South America, the barren lunar landscape with a full earth in the dark sky, or the rapids of a fast-moving river. Sabbatical’s BackDrop™ (Figure 9) [http://www.sabbatical.com ] and Reality Fusion’s FreeAction™ Dynamic Layer Transformer (Figure 10) [http://www.realityfusion.com ] both have algorithms for background substitution.
 |
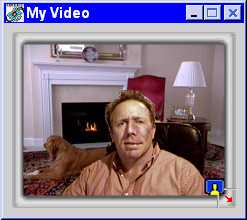 |
Figure 9 |
[Caption: Sabbatical’s BackDrop™ Background Substitution. These two images are found on http://www.sabbatical.com]

[Caption: Reality Fusion’s FreeAction™ Dynamic Layer Transformer. This image is found on http://www.realityfusion.com ]
Shape Recognition. Using various analysis techniques, model-based object recognition algorithms locate regions containing the same or nearly the same color (color blobs), boundaries between two regions of different color (edges), or other features. These features may be classified into shapes and interpreted as objects. For example, blue blobs can be located within a scene and compared to a template containing the shape of a gun. The computer recognizes not only the presence of the gun, but also its orientation within the image.
Reality Fusion’s FreeAction™ Known Object Detector recognizes the orientation of a gun. Using this technology, an application calculates the direction of projectiles from the gun’s barrel and whether the projectile will intersect any of several virtual fish (Figure 11). In the MIT KidsRoom, this technology is used to determine the orientation of the bed and the basic shapes of the children within the room.

[Caption: Reality Fusion’s FreeAction™ Known Object Reactor. This figure is found on http://www.realityfusion.com ]
Face Recognition. Recognizing a person’s face involves identifying features that correspond to parts of the face, such as eyes, nostrils, lips, chin, and hairline; scaling and rotating the features to a standard size and format; and, finally, comparing the features to sets of features belonging to specific individuals.
Face recognition applications are useful within a screen saver. Traditionally, users entered a password to remove a screen saver display their monitors to reveal the user’s active programs and computer desktop. Face recognition technology eliminates the need for a password by recognizing when the user is in front of the display device. Face recognition also can be used to restrict children from accessing Web pages deemed undesirable by their parents. In order to detect when a user is trying to trick the face recognition algorithm by holding a picture of another person in front of the camera, the recognition algorithm may require the user to speak or move. Through a combination of lip movement detection and audio identification of the speaker, some face recognition algorithms have been extended to detect the difference between a picture and a real person. There are several face recognition packages available, including TrueFace from Miros [http://www.miros.com], FaceKey™ from IVI [http://www.wp.com/IVS_face], FaceIt« from Visionics [http://www.FaceIt.com/live/main.htm], and Face ID™ from Image Ware [http://www.iwsinc.com/crimes/faceid.htm]. Face recognition is one of several biometric techniques for recognizing humans. Other biometric techniques include thermograms (heat maps of the face), voice features and characteristics, fingerprints, and retina patterns.
MOTION TRACKING/INTERPRETATION
In Figure 8, the right column lists object movements, activities, and actions that can be recognized in a video. Movements are detected by comparing the position of an object across multiple frames of the video. In some cases, a sequence of movements can be classified into an activity. It also may be possible to interpret a high-level action from a sequence of activities.
Object Movement. It is possible to compare the location of objects in successive frames. This type of motion detection is useful for security applications where movement in specific areas should be detected; but movement in other areas, such as waving trees or busy sidewalks, should be ignored. Object movement was also used in the KidsRoom to determine from which side of the bed the children waved their arms. For each side of the bed, the differences in object locations are summed over successive frames. The side of the bed with the highest score is determined to have the greatest amount of "rowing." This causes the displayed video to change to reflect the direction of the bed with respect to the virtual river.
In addition to detecting motion, it is possible to calculate the general direction of object motion. Movements of objects corresponding to users or user body parts enable a variety of computer games. For example, in Reality Fusion’s FreeAction™ Human Object Reactor users "hit" a virtual basketball, causing the ball to move at a speed and direction proportional to the speed and direction of the user’s hand.
In Figure 13, Thundercam™ from Holoplex [http://www.holoplex.com] uses video cameras and gesture recognition to turn a player’s physical moves into animated kickboxer jumps and kicks. Captured video images are analyzed and compared to a set of predefined body gestures recognized by the system. This technology can work, in principle, with any game that uses a joystick with some software modification.

[Figure 13. Caption: Holoplex’s Thundercam™. The picture is taken from http://www.holoplex.com/thundercam ]
Object Activity. Children in the KidsRoom are encouraged to make four gestures: crouching, positioning their arms to make a "Y," flapping their arms, and spinning their bodies. In effect the children train the system to recognize each of these four gestures and interpret them as activities. Then, the animated monster performs the same activity as the children did.
Microsoft’s Matthew Turk has developed vision-driven activities for children, where the computer recognizes several user activities and responds with specific sounds for each activity. These include the following:
[http://www.microsoft.com/billgates/speeches/pdc.html—Bill Gates’ remarks on September 26, 1997.]
Object Action. An action can be inferred from a sequence of activities. For example, a football player first runs to the left, then runs to the right. This action is called an end-run-around play. While he was at the MIT Media Laboratories, Aaron Bobick developed an algorithm to examine videotape of football games to deduce some of the team plays—actions inferred from sequences of various activities. This example can be found at [http://vismod.www.media.mit.edu/mismod/demos/football/actions.html]. Context is necessary to interpret activities into action. In another context, the action of moving first to the left and then moving forward could be interpreted as a man walking in a strong wind or as a man who had too much to drink at a party.
VISION APPLICATIONS
There is a large variety and breadth of potential applications using vision—video image and video motion recognition.
Security. Motion detection is widely used in surveillance applications. Face recognition can be used for a variety of applications, including:
Manufacturing. Specialized manufacturing applications include:
Robotics. These applications include:
Entertainment. Entertainment applications include:
Conferencing. Applications for conferencing include:
Self-improvement and Training. Specialized training applications include:
PRACTICAL ADVICE
Because the design of vision applications is a new field of endeavor, general guidelines are just beginning to emerge. However, earlier speech recognition guidelines can be generalized for use in vision applications, as shown in Table 1.
| Speech Recognition Guidelines | Vision Guidelines | KidsRoom Example |
| Train the system to recognize each user’s speech | Train the system to recognize each user’s gestures | Data about the children’s gestures were recorded as the monsters showed the children how to make monster gestures (crouch, make a "Y", flap arms, and spin bodies). The KidsRoom later used this data to recognize the children’s gestures. |
| Provide context in which a small vocabulary of words can be recognized | Provide context in which a small number of gestures can be recognized | The children’s rowing gesture is recognized only when the children are on the bed. The children’s monster movements are recognized only when a child stands in front of a monster. |
| Have several backup questions if the user fails to respond correctly | Have several backup narrations in addition to a final narration for "move-on anyway" situations for every story decision point | If all the children do not get onto the bed after the first request, the voice becomes stronger and more threatening. |
| Keep the numbers of words in the speech recognition vocabulary small | Keep the number of gestures in the gesture recognition vocabulary small | Only four monster gestures were possible: crouch, make a "Y," flap arms, and spin bodies |
| Use speech inputs that sound distinctly different from each other | Use gesture inputs that are visibly different from each other | The four gestures are very different from each other. The "Y" and the arm flap are quite different temporally because the "Y" has little movement after the initial arm lift. |
| Provide immediate feedback for every speech input | Provide immediate feedback for every gesture input | The boat turns when the children row. Monsters mimic the gestures as the children perform the monster gestures. |
Table 1—Speech and Vision Guidelines
For additional advice, see http://vismod.www.media.mit.edu/vismot/demos/kidsroom/design.htm for observations and comments from the developers of the KidsRoom.
With the emergence of vision technologies, new applications will be possible. Natural movements and gestures, combined with speech recognition, will enable a new age of human-computer interaction.
James A. Larson is the Manager of Advanced Human I/O at the Intel Architecture Labs in Hillsboro, OR. He can be reached at lartech@easystreet.com.
® 1997, 1998 CI Publishing À All rights reserved. Not to be reprinted or
redistributed in any form without written permission.